Assistant Professor - Digital Future Lab - Hasselt University

Research Projects
2025-2029
 |
Accurate large-area Localization and spatial Alignment with Robust Markerless Methods (ALARMM SBO)
There are numerous industrial needs for accurate and robust 3D localization in large-scale indoor
shopfloors, with ALARMM_SBO focusing on (1) location-sensitive cognitive assistance via Augmented
Reality (AR) guidance for production employees, and (2) autonomous vehicles (i.e., AMRs) executing
fine-grained tasks like machine tending. Typical localization approaches use local alignment by
exploiting complex data-driven 6DOF pose estimation of objects (which is unreliable and time-
consuming to scale to large environments), apply outside-in tracking with external devices or dedicated
infrastructure (which is expensive), use graphical markers for spatial reference (which can be
impractical in large industrial shopfloors), or use visual SLAM. While cost-effective, SLAM-based
solutions are prone to drift, especially in shopfloor-wide scenarios, and are not robust to varying
operational conditions (e.g., low-light or low-texture environments) nor in dynamic environments
which, in worst cases, can render the localization system entirely unreliable.
ALARMM_SBO will improve the accuracy, reliability and robustness of SLAM-based localization by
jointly exploiting (1) graphical factory representations (e.g., drift-free 3D shopfloor scan or globally
aligned CAD models), (2) semantic knowledge about the industrial environment, (3) known dynamic
models of machines, and (4) Deep Learning-based IMU localization. Each of these four elements will
output specific constraints on the localization optimization process and will be integrated in a smart
uncertainty-based constraint selection module to maximize its impact on accuracy, reliability and
robustness, tailored to the application’s needs. This will yield high frame-rate 3D global localization
with at most 1cm spatial accuracy tolerance in large-area indoor shopfloors when sufficient visual
features are present, and a robust graceful degradation towards 5cm in the case of more challenging
low-light and low-texture environments.
|
2025-2027
|
Active Defects Detection In Line (ADDIL IRVA)
The ADD-IL project targets the inline inspection of surface defects (and other small surface details) of
(moving) parts in a production floor.
In practise, comparable systems are often commercially viable only in case of high volume production,
e.g. in automotive. Indeed, these high volumes justify the huge investment needed to make vision
tunnels creating a fully controlled environment, hiring experts to training vision models, automation
engineers to program robots, etc. The goal of this project is to prove that similar solutions can also
be made accessible for high-mix production and deal intelligently with high production variability.
There are various technical barriers to solve this problem. First, a high-mix environment is much less
predictable and inherently has more variability. Second, the introduction of a new part should be
sufficiently fast both in terms of design and commissioning. More detailed elaboration of concrete
technical barriers is given in the next section.
The project tackled these barriers in an end-to-end approach, starting from the creation of design
tools to build optimal automated inspection systems and going up to the creation of state-of-the-art
multi-image defect detection algorithms capable of reducing false positive/negative rates with 50%
w.r.t. state-of-the-art single-image approaches. The project is building upon the results developed in
the Flanders Make ADAVI ICON2 project and extending the challenges to deal with larger parts (> 1m3)
and uncontrolled conditions in production floors (unknown pose and/or CAD-file, uncontrolled
lighting, etc.).
Typical use-cases that will be investigated are the inline inspection in painting production lines of
unpainted and / or painted parts hanging from a trolley while the parts are prepared for painting and
/ or the paint is drying. As a challenge example, the glossy nature of the parts together with the
variable ambient lighting makes it very difficult to design an automated off-the-shelf inspection setup
having correct lighting to detect the different defects. As a result, inspection is typically performed by
humans once the paint has dried. However, significant economic benefits can be obtained if this
process could be performed in a more traceable and reliable way by an actuated (set of) optimized
camera(s) system coupled to a performant deep learning computer vision algorithm. This is the main
goal of ADD-IL.
To accelerated the lead time of the E2E solution, the project will develop a standardized workflow
integrating the above elements. As a result, compared to what is possible today, for the surface defect
detection of a new part using existing inspection hardware: (i) the design will be completely offline
(avoiding production downtime) and 3 times faster, (ii) the commissioning (online) will also be 3 times
faster.
|
2023-2027
|
Natural Objects Rendering for Economic AI Models (NORM.AI)
Natural objects (vegetables, fruits, food, etc.) are omnipresent in different industrial applications: food sorting, vegetable spray treatments, precision & automated farming, etc. Automating these applications to deal with large variabilities of natural objects (object's detection, recognition, pose estimation, etc.), requires innovative technologies that are enabled by Artificial Intelligence (AI) that has the ability to generalize to variabilities. However, training these AI models would require thousands of images / videos with detailed annotations of different items. In the state of the art, one needs >10k images to (re-)train an AI model with an accuracy of >90%, when, in average one minute is needed to annotate one 'real' image, however these can increase drastically depending on the use case at hand and the variability around it. The more variability one wants to cover, the more training images are needed. These findings clearly indicate that in order to be able to deploy AI models in the industrial applications, innovative techniques are highly needed to remove the burdens of data annotations. These techniques need also to be easily usable by end users to avoid large amount of manual work to update the proposed methodology to new applications. NORM.AI builds further on the successful results from PILS SBO, where rendering techniques were applied to industrial products with CAD (Computer Aided Design) information, to retrieve AI (synthetic) training data from updated CAD with radiance models. While CAD facilitates synthetic data generation in PILS SBO by providing a reference model to start rendering from, the goal of NORM.AI project is to extend this research to Natural objects where no CAD is available. Therefore, defining a reference model to start rendering from, is part of the research in the project. Creating variations from the reference model that takes both spatial & time changes of the natural objects and the natural scenes, as well as finding a sweet spot between real data augmentation techniques & synthetic data generation techniques constitute another research challenge in the project. This research will allow to identify economic scenarios of training data generation, taking into account their effect into AI model's accuracy and robustness. The project focuses into three research applications: 1. Food sorting applications, where 2D images are used to detect & sort fruits & vegetables, as they are coming, for example, in a conveyor system. 2. Crop monitoring applications, where images from 2D cameras, for example, installed in a harvester, are used to detect vine's rows, crop distribution, etc.\ 3. Weed monitoring applications, where 2D images guide a spraying system to locally spray weeds in a high precision.
|
2022-2025
 |
MAX-R (EU Innovation Action)
MAX-R is a 30-month IA that will define, develop and demonstrate a complete pipeline of tools for making, processing and delivering maximum-quality XR content in real time. The pipeline will be based on open APIs, open file and data transfer formats to encourage development and support the integration of new open source and proprietary tools. MAX-R builds on recent research and advances in Virtual Production technologies to develop real-time processes to deliver better quality, greater efficiency, enhanced interactivity, and novel content based on XR media data. The interdisciplinary Consortium of eleven partners from five countries covers the chain from technology development and product innovation to creative experiment and demonstration, and from XR media creation to delivery to the final consumer. It is built around Europe’s leading media technology developers, together with creative organisations operating in AR/VR/MR, Virtual Production, interactive games, new media, TV, video and news, multimedia and immersive performance.
[website]

|
2022-2025
|
FARAD2SORT ICON
Deep learning is an artificial intelligence technology that has shown great potential in a large variety of applications (Figure 1). When applied to image analysis, it is an essential enabler for automation of repetitive but complex quality inspection tasks, development of robots that can recognize and manipulate objects, etc. So far, the use of this powerful technology requires deep technical knowledge of training strategies and a large amount of hand-annotated images, i.e. a long and costly development process. Currently the deployment of this technology delivers inconsistent results of variable performance, and it is difficult to debug and maintain. The goal of the FARAD2SORT project is to realize a technological framework to help engineers that have a general understanding of deep learning technology, but are not experts in it, to design, develop, and deploy deep learning vision based on 2D images for applications that require industrial object detection, object recognition and surface defects / anomaly detection & classification. The FARAD2SORT results will build on existing open-source deep learning software by adding tools that will make implementation easier, cheaper and more accurate and robust.
|
2019-2023
|
PILS SBO
The project aims to reduce the deployment costs of computer vision systems for quality control in manufacturing and assembly, by virtue of requiring less data acquisition and labeling effort (i.e. supervision) while increasing the robustness. The main goal of this project is to research how the amount of real-world training data can be reduced to make visual inspection algorithms work in a low volume manufacturing context. A common approach to cope with a small training data set is data augmentation: slightly distorting the available data points to create new points that still belong to the same category. In vision, this usually consists of randomly applying straightforward variations such as cropping, rotating, scaling, mirroring, color balancing, and/or adjusting brightness of the entire collection of training pictures to create many slightly modified copies. The actual products are three-dimensional objects and their visual appearance is governed by complex material properties, lighting conditions, and geometrical detail. This project will try to accomplish this by integrating computer graphics and computer vision technology to generate synthetic variations of the above-mentioned complex visual effects. Furthermore, synthetic defects can be introduced. In this way, a large labelled synthetic data set is obtained and can be used as training input for a visual inspection algorithm. The framework developed in this project can be used to significantly accelerate the development of specialized machine learning algorithms to identify a product, perceive its pose, detect defects, and track the progress of assembly.
[website]
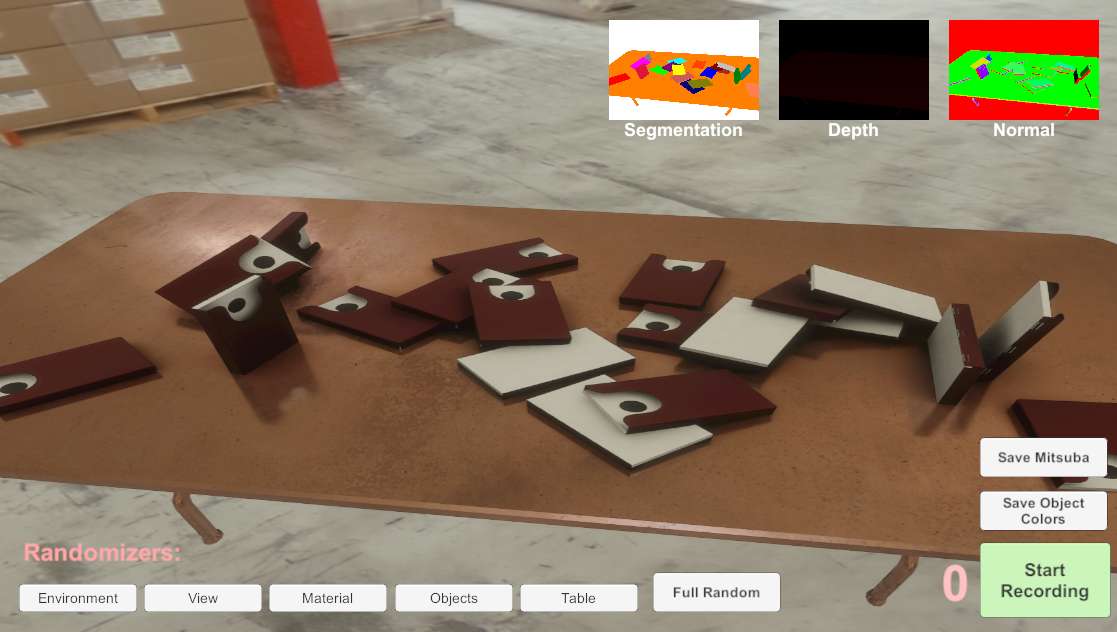
|
2018-2020
 |
FLEXAS-VR SBO
An image-based capturing method of assembly workstation resources. This task will focus on setting up such an image-based capturing approach. The initial focus will be
on a monocular handheld capturing device, such as a portable camera. Poses of the camera will be
estimated by using a Simultaneous Localization and Mapping (SLAM) algorithm or an offline
calibration process. Depending on the required quality, certain markers will have to be placed within
the captured scene. Otherwise, natural feature tracking will be utilized as a fallback approach. Once
the images are captured, they will have to be compressed in a format that allows rapid low-latency
streaming and decoding on the GPU. Most existing compression formats, such as H.264, are
sequential in nature and do not allow for random access to frames. In this task, an efficient retrieval
scheme will be devised to get around this limitation.
[website]

|
2018-2019
  |
ImmCyte - Immuno Cytometry
This project’s aim is to improve insight in and exploit immune cell complexity in chronic infection disease models and in neurodegeneration, by means of new cellular phenotyping technologies (Single Cell Sequencing and Multi-Parametric High-Content Imaging on non-adherent cells).
Single-Cell Image and Data Analysis: To develop methods for large scale data handling and processing (>10X to current image sets from standard High-Content Imaging) To develop methods for cell segmentation, feature extraction and cell classification To enable analysis of large scale heterogeneous cell populations, utilizing high-dimensional phenotypic signatures |
2017
|
2015-2016
 |
HiViZ - iMinds visualization research program
[website]
|
2011-2015
 |
Remixing Reality
Computer-generated graphics and imagery have become ubiquitous in numerous fields including film, computer games, medical and scientific visualization, architecture, tele-collaboration, virtual walkthroughs, advertising, and social internet applications. However, generating and integrating truly realistic synthetic imagery and photographs or video remains cumbersome, challenging and prohibitively computationally expensive. We propose to overcome these difficulties by developing a novel representation of moving 3D objects and scenery, that will bridge the gap between geometry-based approaches (such as triangle meshes) traditionally used for modeling and rendering, and pixel-based approaches traditionally used for images and videos. By combining the advantages of both approaches, we will enable new applications such as interactively navigating 3D video environments augmented with virtual objects (and vice versa) while maintaining fully realistic appearance and lighting.
|
2011-2014
 |
SCENE - Novel Scene Representation for Richer Networked Media (EU)
The objective is to create and deliver richer media experiences. The SCENE representation and its associated tools will make it possible to capture 3D video, combine video seamlessly with CGI, and manipulate and deliver it to either 2D or 3D platforms in either linear or interactive form.
[website]
Scene researches, develops and demonstrates:
|