Assistant Professor - Digital Future Lab - Hasselt University

Publications
2025
 |
Real-time Neural Rendering of LiDAR Point Clouds Joni Vanherck, Brent Zoomers, Tom Mertens, Lode Jorissen, and Nick Michiels. In proceedings of Eurographics 2025 - Short Papers, London, UK, 2025. AbstractStatic LiDAR scanners produce accurate, dense, colored point clouds, but often contain obtrusive artifacts which makes them ill-suited for direct display. We propose an efficient method to render photorealistic images of such scans without any expensive preprocessing or training of a scene-specific model. A naive projection of the point cloud to the output view using 1x1 pixels is fast and retains the available detail, but also results in unintelligible renderings as background points leak in between the foreground pixels. The key insight is that these projections can be transformed into a realistic result using a deep convolutional model in the form of a U-Net, and a depth-based heuristic that prefilters the data. The U-Net also handles LiDAR-specific problems such as missing parts due to occlusion, color inconsistencies and varying point densities. We also describe a method to generate synthetic training data to deal with imperfectly-aligned ground truth images. Our method achieves real-time rendering rates using an off-the-shelf GPU and outperforms the state-of-the-art in both speed and quality.
![[Uncaptioned image]](https://arxiv.org/html/2502.11618v1/x2.png)
|
 |
Automated Skeleton Transformations on 3D Tree Models Captured from an RGB Video Joren Michels, Steven Moonen, Enes Guney, Abdellatif Bey-Temsamani and Nick Michiels. In proceedings of Eurographics 2025 - Short Papers, London, UK, 2025. AbstractA lot of work has been done surrounding the generation of realistically looking 3D models of trees. In most cases, L-systems are used to create variations of specific trees from a set of rules. While achieving good results, these techniques require knowledge of the structure of the tree to construct generative rules. We propose a system that can create variations of trees captured by a single RGB video. Using our method, plausible variations can be created without needing prior knowledge of the specific type of tree. This results in a fast and cost-efficient way to generate trees that resemble their real-life counterparts. |
 |
PRoGS: Progressive Rendering of Gaussian Splats Brent Zoomers, Maarten Wijnants, Ivan Molenaers, Joni Vanherck, Jeroen Put, Lode Jorissen, and Nick Michiels. In 2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Tucson, AZ, USA, 2025, pp. 3118-3127. AbstractOver the past year, 3D Gaussian Splatting (3DGS) has received significant attention for its ability to represent 3D scenes in a perceptually accurate manner. However, it can require a substantial amount of storage since each splat's individual data must be stored. While compression techniques offer a potential solution by reducing the memory footprint, they still necessitate retrieving the entire scene before any part of it can be rendered. In this work, we introduce a novel approach for progressively rendering such scenes, aiming to display visible content that closely approximates the final scene as early as possible without loading the entire scene into memory. This approach benefits both on-device rendering applications limited by memory constraints and streaming applications where minimal bandwidth usage is preferred. To achieve this, we approximate the contribution of each Gaussian to the final scene and construct an order of prioritization on their inclusion in the rendering process. Additionally, we demonstrate that our approach can be combined with existing compression methods to progressively render (and stream) 3DGS scenes, optimizing bandwidth usage by focusing on the most important splats within a scene. Overall, our work establishes a foundation for making remotely hosted 3DGS content more quickly accessible to end-users in over-the-top consumption scenarios, with our results showing significant improvements in quality across all metrics compared to existing methods.
![[Uncaptioned image]](https://arxiv.org/html/2409.01761v1/x1.png)
|
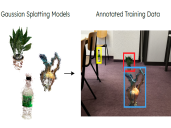 |
Cut-and-Splat: Leveraging Gaussian Splatting for Synthetic Data Generation Bram Vanherle, Brent Zoomers, Jeroen Put, Frank Van Reeth and Nick Michiels. Accepted at ROBOVIS 2025: International Conference on Robotics, Computer Vision and Intelligent Systems. Won Best Paper Award! AbstractGenerating synthetic images is a useful method for cheaply obtaining labeled data for training computer vision models. However, obtaining accurate 3D models of relevant objects is necessary, and the resulting images often have a gap in realism due to challenges in simulating lighting effects and camera artifacts. We propose using the novel view synthesis method called Gaussian Splatting to address these challenges. We have developed a synthetic data pipeline for generating high-quality context-aware instance segmentation training data for specific objects. This process is fully automated, requiring only a video of the target object. We train a Gaussian Splatting model of the target object and automatically extract the object from the video. Leveraging Gaussian Splatting, we then render the object on a random background image, and monocular depth estimation is employed to place the object in a believable pose. We introduce a novel dataset to validate our approach and show superior performance over other data generation approaches, such as Cut-and-Paste and Diffusion model-based generation. |
 |
Projector-Camera Calibration with Non-overlapping Fields of View Using a Planar Mirror Joni Vanherck, Lode Jorissen, Brent Zoomers and Nick Michiels. Published in Springer Virtual Reality, Volume 29, article number 19, 2025.
[doi]
AbstractProjector-camera systems have numerous applications across diverse domains. Accurate calibration of both intrinsic and extrinsic parameters is crucial for these systems. Intrinsic parameters include focal length, distortion parameters, and the principal point, while extrinsic parameters encompass the position and orientation of the projector and camera. A non-overlapping projector-camera system is required in certain scenarios due to practical limitations, physical arrangements, or specific application requirements. These systems pose a more complex calibration challenge because the devices have no direct correspondences or overlapping fields of view, necessitating intermediate objects or methods. This paper proposes a calibration method for non-overlapping projector-camera systems using a planar mirror. The method involves a straightforward process that requires a calibrated camera and a separate mirror calibration step. In this setup, the projector displays a pattern on a planar calibration board, and the camera has an indirect view of this calibration board through the mirror. Using homography, 3D-2D correspondences of the projector are established, enabling the calibration of the system. This method is empirically evaluated using real-world setups and quantitatively assessed in a synthetic environment. The results demonstrate that the proposed method achieves precise calibration across various setups, proving its effectiveness. This approach is an easy-to-use and accessible calibration process for non-overlapping projector-camera systems, made possible by a mirror.
|
2024
 |
Large-area Tracking and Rendering for Extended Reality Nick Michiels, Lode Jorissen, Fabian Di Fiore, Kristof Overdulve, Joni Vanherck, Isjtar Vandebroeck, Haryo Sukmawanto and Eric Joris. Oral presentation and demo at the Stereopsia Scientific Conference. AbstractAs extended reality (XR) technologies continue to evolve, the potential for larger and more immersive experiences grows. However, one of the key challenges in expanding XR applications beyond small, room-sized environments is the issue of tracking accuracy over larger areas. Current XR headsets, primarily designed for living room-scale games, training sessions, or performances, are prone to drift when used in more extensive settings. This drift leads to a misalignment between the virtual and physical worlds, which undermines the immersive experience and presents significant technical barriers for applications requiring precise spatial alignment.This presentation introduces a groundbreaking approach to overcoming these challenges, focusing on recent advancements in large-area tracking and visualization. We will discuss how novel solutions developed by the research team at UHasselt, in collaboration with creative industry partner CREW, can be applied to scale up live cultural performances and various industrial use cases. Our approach integrates existing off-the-shelf XR headsets tracking technologies with newly developed tracking technologies that aims to mitigate the drift issue. By leveraging physical ground truth landmarks within the environment and adapting a SLAM-based (Simultaneous Localization and Mapping) tracking algorithm, we have enhanced the ability of XR systems to maintain precise alignment over larger indoor areas. This advancement not only preserves the immersive quality of the XR experience but also opens up new possibilities for applications that require expansive and challenging indoor environments. 

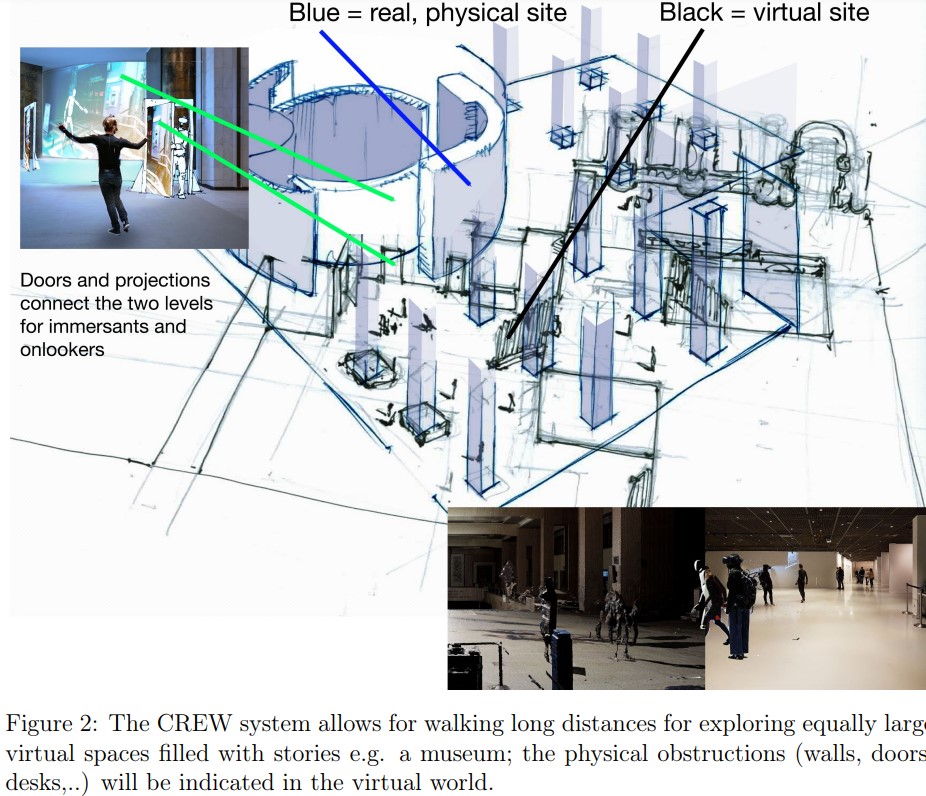
|
 |
3D-HRFC: 3D-Aware Image Generation at High Resolution with Faster Convergence Qiqiang Xia, Junhong Chen, Tianxiao Li, Yiheng Huang, Muhammad Asim, Nick Michiels and Wenyin Liu. In proceedings of PRICAI 2024: Trends in Artificial Intelligence.
[doi]
AbstractLearning 3D-aware generators from 2D image collections has attracted significant attention in the field of generative modeling. However, there are several challenges in generating high-resolution multi-view consistent images, e.g., 2D CNN-based approaches leverage upsampling layers to generate high-resolution images, easily resulting in inconsistencies across multi-view images; methods that generate images based on NeRF require tremendous memory space and a long time to converge. To this end, we propose a novel 3D-aware generative method named 3D-HRFC to generate high-resolution consistent images with faster convergence. Specifically, we first propose a depth fusion based super-resolution module that integrates the depth maps into the low-resolution images in order to generate consistent multi-view images. And then a skip super-resolution module is devised to enhance the generation of the high-resolution images. To generate high-resolution consistent images and accelerate the model convergence, we devise a composite loss function that consists of adversarial loss, super-resolution loss, and content consistency. Extensive experiments conducted on FFHQ and AFHQ-v2 Cats datasets illustrate that our proposed method can generate high-quality 3D-consistent images. |
 |
VATr++: Choose Your Words Wisely for Handwritten Text Generation Bram Vanherle, Vittorio Pippi, Silvia Cascianelli, Nick Michiels, Frank Van Reeth, Rita Cucchiara. In IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI 2024). AbstractStyled Handwritten Text Generation (HTG) has received significant attention in recent years, propelled by the success of learning-based solutions employing GANs, Transformers, and, preliminarily, Diffusion Models. Despite this surge in interest, there remains a critical yet understudied aspect - the impact of the input, both visual and textual, on the HTG model training and its subsequent influence on performance. This work extends the VATr [1] Styled-HTG approach by addressing the pre-processing and training issues that it faces, which are common to many HTG models. In particular, we propose generally applicable strategies for input preparation and training regularization that allow the model to achieve better performance and generalization capabilities. Moreover, in this work, we go beyond performance optimization and address a significant hurdle in HTG research - the lack of a standardized evaluation protocol. In particular, we propose a standardization of the evaluation protocol for HTG and conduct a comprehensive benchmarking of existing approaches. By doing so, we aim to establish a foundation for fair and meaningful comparisons between HTG strategies, fostering progress in the field. |
 |
Active learning for quality inspecting with synthetic hot- start approach Aaron De Rybel, Steven Moonen, Nick Michiels, Sam Dehaeck. Presentation at the The 24th annual conference of the European Network for Business and Industrial Statistics (EMBIS), Leuven, Belgium, 2024, September 16-18.
[uri] [presentation]
AbstractIn the pharmaceutical industry, there are strict requirements on the presence of contaminants inside single-use syringes (so-called unijects). Quality management systems include various methods such as measuring weight, manual inspection or vision techniques. Automated and accurate techniques for quality inspection are preferred, reducing the costs and increasing the speed of production. In this paper we analyze defects on unijects. During inspection, the product is spun around to force contaminants to the outside of the bulb and photos are taken. These photos can be manually inspected, however using computer vision techniques this process can be automated. As such inclusions are exceedingly rare to occur in practice, it is very difficult to collect a first dataset to train a deep-learning network on, which contains actual defects. The approach we will demonstrate in our contribution introduces synthetic defects on top of regular images for kickstarting the defect detection network. Using this initial defect segmentation network, we can then introduce classic uncertainty and diversity sampling algorithms to select relevant images for annotation. Normally, in these 'active learning' strategies the initial dataset is taken at random. However, because of the low probability of selecting each type of defect at random, the model has a very cold start. We will demonstrate how our hot-start approach using synthetic defects solves this initialization problem. |
 |
Large-area Spatially Aligned Anchors Joni Vanherck, Brent Zoomers, Lode Jorissen, Isjtar Vandebroeck, Eric Joris and Nick Michiels. In proceedings of the International Conference on Extended Reality Salento (Salento XR '24). De Paolis, L.T., Arpaia, P., Sacco, M. (eds) Extended Reality. Salento XR 2024. Lecture Notes in Computer Science, vol 15027. Springer, Cham. AbstractExtended Reality (XR) technologies, including Virtual Reality (VR) and Augmented Reality (AR), offer immersive experiences merging digital content with the real world. Achieving precise spatial tracking over large areas is a critical challenge in XR development. This paper addresses the drift issue, caused by small errors accumulating over time leading to a discrepancy between the real and virtual worlds. Tackling this issue is crucial for co-located XR experiences where virtual and physical elements interact seamlessly. Building upon the locally accurate spatial anchors, we propose a solution that extends this accuracy to larger areas by exploiting an external, drift-corrected tracking method as a ground truth. During the preparation stage, anchors are placed inside the headset and inside the external tracking method simultaneously, yielding 3D-3D correspondences. Both anchor clouds, and thus tracking methods, are aligned using a suitable cloud registration method during the operational stage. Our method enhances user comfort and mobility by leveraging the headset's built-in tracking capabilities during the operational stage, allowing standalone functionality. Additionally, this method can be used with any XR headset that supports spatial anchors and with any drift-free external tracking method. Empirical evaluation demonstrates the system's effectiveness in aligning virtual content with the real world and expanding the accurate tracking area. In addition, the alignment is evaluated by comparing the camera poses of both tracking methods. This approach may benefit a wide range of industries and applications, including manufacturing and construction, education, and entertainment. |
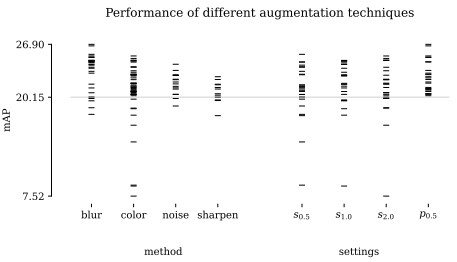 |
Genetic Learning for Designing Sim-to-Real Data Augmentations Bram Vanherle, Nick Michiels and Frank Van Reeth. In International Conference on Learning Representations (ICLR 2024) Workshop on Data-centric Machine Learning Research (DMLR). AbstractData augmentations are useful in closing the sim-to-real domain gap when training on synthetic data. This is because they widen the training data distribution, thus encouraging the model to generalize better to other domains. Many image augmentation techniques exist, parametrized by different settings, such as strength and probability. This leads to a large space of different possible augmentation policies. Some policies work better than others for overcoming the sim-to-real gap for specific datasets, and it is unclear why. This paper presents two different interpretable metrics that can be combined to predict how well a certain augmentation policy will work for a specific sim-to-real setting, focusing on object detection. We validate our metrics by training many models with different augmentation policies and showing a strong correlation with performance on real data. Additionally, we introduce GeneticAugment, a genetic programming method that can leverage these metrics to automatically design an augmentation policy for a specific dataset without needing to train a model. |
 |
DistillGrasp: Integrating Features Correlation with Knowledge Distillation for Depth Completion of Transparent Objects Y. Huang, Junhong Chen, Nick Michiels, M. Asim, L. Claesen and W. Liu. In: IEEE Robotics and Automation Letters.
[doi]
AbstractDue to the visual properties of reflection and refraction, RGB-D cameras cannot accurately capture the depth of transparent objects, leading to incomplete depth maps. To fill in the missing points, recent studies tend to explore new visual features and design complex networks to reconstruct the depth, however, these approaches tremendously increase computation, and the correlation of different visual features remains a problem. To this end, we propose an efficient depth completion network named DistillGrasp which distillates knowledge from the teacher branch to the student branch. Specifically, in the teacher branch, we design a position correlation block (PCB) that leverages RGB images as the query and key to search for the corresponding values, guiding the model to establish correct correspondence between two features and transfer it to the transparent areas. For the student branch, we propose a consistent feature correlation module (CFCM) that retains the reliable regions of RGB images and depth maps respectively according to the consistency and adopts a CNN to capture the pairwise relationship for depth completion. To avoid the student branch only learning regional features from the teacher branch, we devise a distillation loss that not only considers the distance loss but also the object structure and edge information. Extensive experiments conducted on the ClearGrasp dataset manifest that our teacher network outperforms state-of-the-art methods in terms of accuracy and generalization, and the student network achieves competitive results with a higher speed of 48 FPS. In addition, the significant improvement in a real-world robotic grasping system illustrates the effectiveness and robustness of our proposed system. |
 |
Brains Over Brawn: Small AI Labs in the Age of Datacenter-Scale Compute Jeroen Put, Nick Michiels, Bram Vanherle and Brent Zoomers. In: Fred, A., Hadjali, A., Gusikhin, O., Sansone, C. (eds) Deep Learning Theory and Applications. DeLTA 2024. Communications in Computer and Information Science, vol 2172. Springer, Cham.
[doi]
AbstractThe prevailing trend towards large models that demand extensive computational resources threatens to marginalize smaller research labs, constraining innovation and diversity in the field. This position paper advocates for a strategic pivot of small institutions to research directions that are computationally economical, specifically through a modular approach inspired by neurobiological mechanisms. We argue for a balanced approach that draws inspiration from the brain’s energy-efficient processing and specialized structures, yet is liberated from the evolutionary constraints of biological growth. By focusing on modular architectures that mimic the brain’s specialization and adaptability, we can strive to keep energy consumption within reasonable bounds. Recent research into forward-only training algorithms has opened up concrete avenues to include such modules into existing networks. This approach not only aligns with the imperative to make AI research more sustainable and inclusive but also leverages the brain’s proven strategies for efficient computation. We posit that there exists a middle ground between the brain and datacenter-scale models that eschews the need for excessive computational power, fostering an environment where innovation is driven by ingenuity rather than computational capacity. |
 |
Tracking and co-location of global point clouds for large-area indoor environments Nick Michiels, Lode Jorissen, Jeroen Put, Jori Liesenborgs, Isjtar Vandebroeck, Eric Joris and Frank Van Reeth. In Springer Virtual Reality 2024, 28, 106. AbstractExtended reality (XR) experiences are on the verge of becoming widely adopted in diverse application domains. An essentialpart of the technology is accurate tracking and localization of the headset to create an immersive experience. A subset ofthe applications require perfect co-location between the real and the virtual world, where virtual objects are aligned withreal-world counterparts. Current headsets support co-location for small areas, but suffer from drift when scaling up to largerones such as buildings or factories. This paper proposes tools and solutions for this challenge by splitting up the simultane-ous localization and mapping (SLAM) into separate mapping and localization stages. In the pre-processing stage, a featuremap is built for the entire tracking area. A global optimizer is applied to correct the deformations caused by drift, guided bya sparse set of ground truth markers in the point cloud of a laser scan. Optionally, further refinement is applied by matchingfeatures between the ground truth keyframe images and their rendered-out SLAM estimates of the point cloud. In the second,real-time stage, the rectified feature map is used to perform localization and sensor fusion between the global tracking andthe headset. The results show that the approach achieves robust co-location between the virtual and the real 3D environmentfor large and complex tracking environments.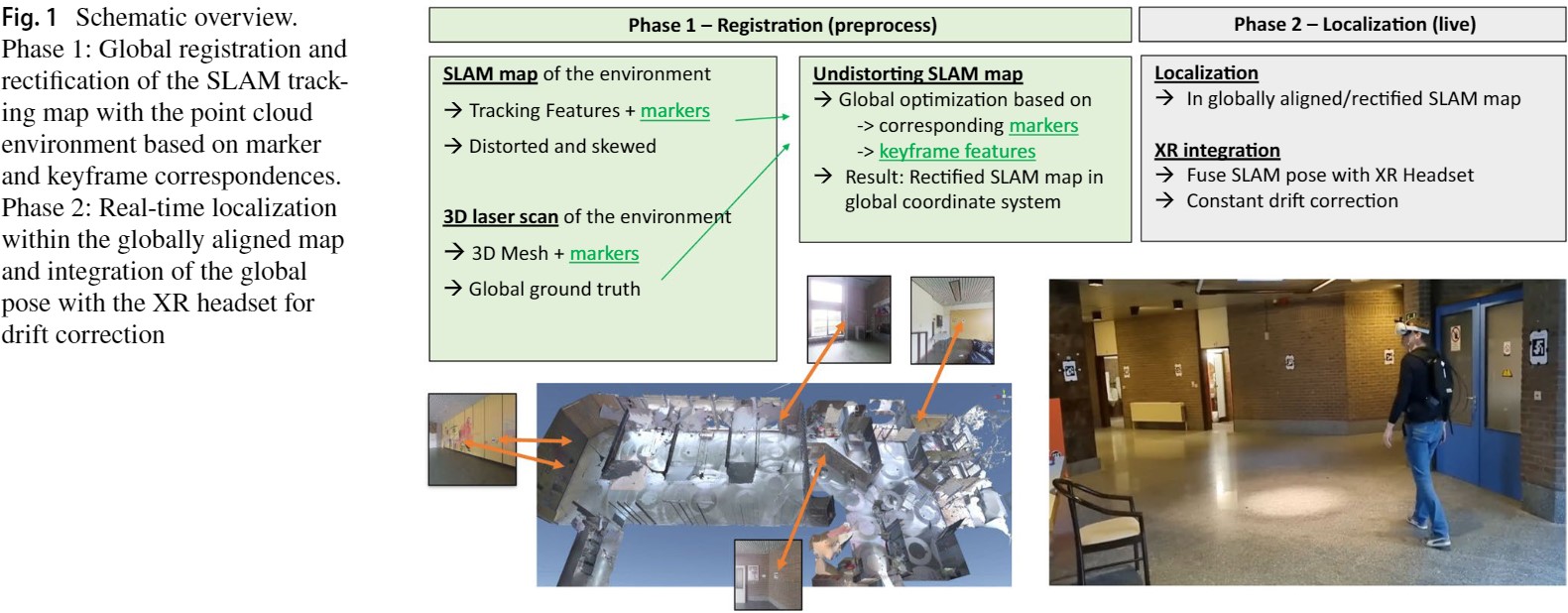
|
 |
Sim-to-Real Dataset of Industrial Metal Objects Peter De Roovere, Steven Moonen, Nick Michiels and Francis wyffels. In Machines 2024, 12(2), 99. AbstractWe present a diverse dataset of industrial metal objects with unique characteristics such as symmetry, texturelessness, and high reflectiveness. These features introduce challenging conditions that are not captured in existing datasets. Our dataset comprises both real-world and synthetic multi-view RGB images with 6D object pose labels. Real-world data were obtained by recording multi-view images of scenes with varying object shapes, materials, carriers, compositions, and lighting conditions. This resulted in over 30,000 real-world images. We introduce a new public tool that enables the quick annotation of 6D object pose labels in multi-view images. This tool was used to provide 6D object pose labels for all real-world images. Synthetic data were generated by carefully simulating real-world conditions and varying them in a controlled and realistic way. This resulted in over 500,000 synthetic images. The close correspondence between synthetic and real-world data and controlled variations will facilitate sim-to-real research. Our focus on industrial conditions and objects will facilitate research on computer vision tasks, such as 6D object pose estimation, which are relevant for many industrial applications, such as machine tending. The dataset and accompanying resources are available on the project website. |
2023
 |
CAD2X - A Complete, End-to-End Solution for Training Deep Learning Networks for Industrial Applications Joris de Hoog, Guillaume Grimard, Taoufik Bourgana, Nick Michiels, Steven Moonen, Roeland De Geest and Abdellatif Bey-Temsamani. In 2023 Smart Systems Integration Conference and Exhibition (SSI).
[doi]
AbstractWith the growing demand for automation in the manufacturing industry, computer vision-based systems have become a popular tool for tasks such as object detection, object picking, and quality control. One of the main challenges in developing such systems is obtaining enough high-quality training data. In this paper, we present a suite of tools that create artificial training data and applies it to solve industrial problems. CAD2Render is a tool for generating synthetic images, starting from a 3D CAD model, which can be used to create large datasets with a large spectrum of controlled variations. CAD2Detect uses these synthetic images to train object detection models. CAD2Pose focuses on estimating the 6 degree of freedom pose of objects in images. Finally, CAD2Defect uses anomaly detection to identify defects in manufactured parts. Overall, the CAD2X suite provides a comprehensive set of tools for training computer vision models for manufacturing applications, while minimizing the need for large amounts of real training data. We demonstrate the effectiveness of our approach on a range of industrial use cases. |
|
 |
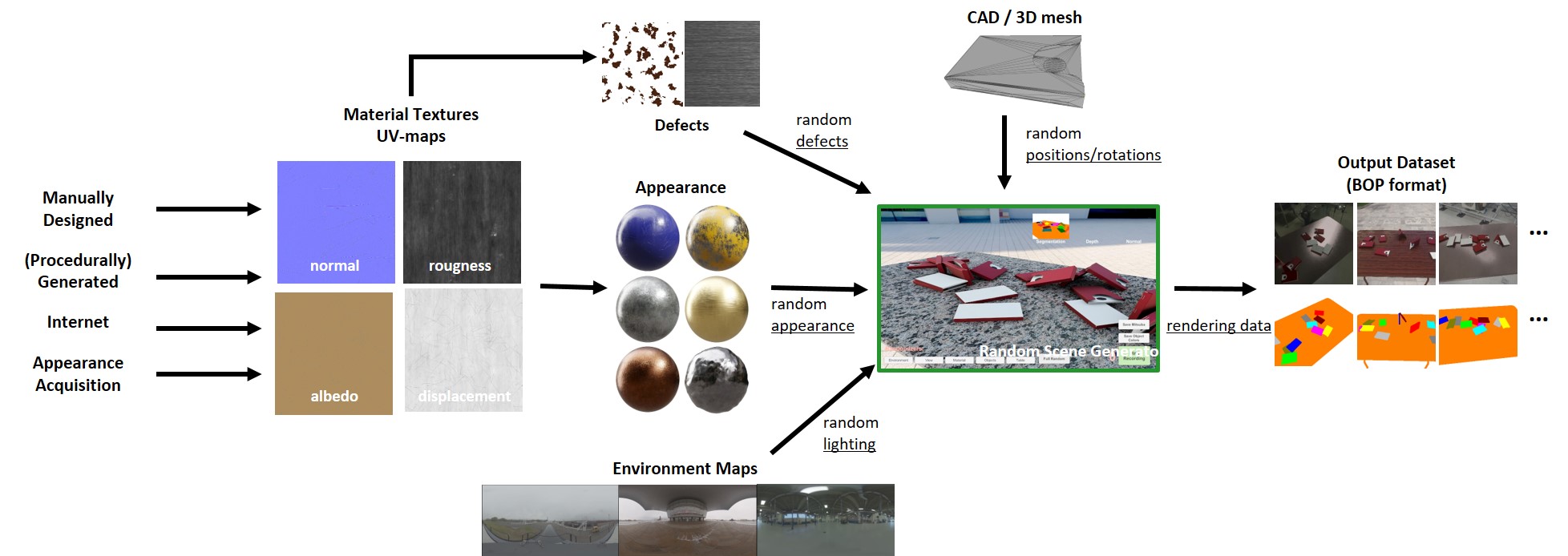
CAD2Render: A Synthetic Data Generator for Training Object Detection and Pose Estimation Models in Industrial Environments Steven Moonen, Bram Vanherle, Joris de Hoog, Taoufik Bourgana, Abdellatif Bey-Temsamani and Nick Michiels In Advances in Artificial Intelligence and Machine Learning Research Journal, 3(2), pp 977-995. AbstractComputer vision systems become more wide spread in the manufacturing industry for automating tasks. As these vision systems use more and more machine learning opposed to the classic vision algorithms, streamlining the process of creating the training datasets become more important. Creating large labeled datasets is a tedious and time consuming process that makes it expensive. Especially in a low-volume high-variance manufacturing environment. To reduce the costs of creating training datasets we introduce CAD2Render, a GPUaccelerated synthetic data generator based on the Unity High Definition Render Pipeline (HDRP). CAD2Render streamlines the process of creating highly customizable synthetic datasets with a modular design for a wide range of variation settings. We validate our toolkit by showcasing the performance of AI vision models trained purely with synthetic data. The performance is tested on object detection and pose estimation problems in a variate of industrial relevant use cases. The code for CAD2Render is available at https://github.com/EDM-Research/CAD2Render. |
|
 |
CAD2Render: A Modular Toolkit for GPU-accelerated Photorealistic Synthetic Data Generation for the Manufacturing Industry Steven Moonen, Bram Vanherle, Joris de Hoog, Taoufik Bourgana, Abdellatif Bey-Temsamani and Nick Michiels 2023 IEEE/CVF Winter Conference on Applications of Computer Vision Workshops (WACVW23)., Waikoloa, HI, USA, 2023, pp. 583-592. AbstractThe use of computer vision for product and assembly quality control is becoming ubiquitous in the manufacturing industry. Lately, it is apparent that machine learning based solutions are outperforming classical computer vision algorithms in terms of performance and robustness. However, a main drawback is that they require sufficiently large and labeled training datasets, which are often not available or too tedious and too time consuming to acquire. This is especially true for low-volume and high-variance manufacturing. Fortunately, in this industry, CAD models of the manufactured or assembled products are available. This paper introduces CAD2Render, a GPU-accelerated synthetic data generator based on the Unity High Definition Render Pipeline (HDRP). CAD2Render is designed to add variations in a modular fashion, making it possible for high customizable data generation, tailored to the needs of the industrial use case at hand. Although CAD2Render is specifically designed for manufacturing use cases, it can be used for other domains as well. We validate CAD2Render by demonstrating state of the art performance in two industrial relevant setups. We demonstrate that the data generated by our approach can be used to train object detection and pose estimation models with a high enough accuracy to direct a robot. The code for CAD2Render is available at https://github.com/EDM-Research/CAD2Render.
|
2022
 |
Analysis of Training Object Detection Models with Synthetic Data Bram Vanherle, Steven Moonen, Frank Van Reeth and Nick Michiels To appear in the proceedings of The 33th British Machine Vision Conference (BMVC 2022). AbstractRecently, the use of synthetic training data has been on the rise as it offers correctly labelled datasets at a lower cost. The downside of this technique is that the so-called domain gap between the real target images and synthetic training data leads to a decrease in performance. In this paper, we attempt to provide a holistic overview of how to use synthetic data for object detection. We analyse aspects of generating the data as well as techniques used to train the models. We do so by devising a number of experiments, training models on the Dataset of Industrial Metal Objects (DIMO)~\cite{DIMO}. This dataset contains both real and synthetic images. The synthetic part has different subsets that are either exact synthetic copies of the real data or are copies with certain aspects randomised. This allows us to analyse what types of variation are good for synthetic training data and which aspects should be modelled to closely match the target data. Furthermore, we investigate what types of training techniques are beneficial towards generalisation to real data, and how to use them. Additionally, we analyse how real images can be leveraged when training on synthetic images. All these experiments are validated on real data and benchmarked to models trained on real data. The results offer a number of interesting takeaways that can serve as basic guidelines for using synthetic data for object detection. Code to reproduce results is available at https://github.com/EDM-Research/DIMO_ObjectDetection. |
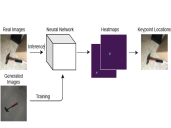 |
Detecting Tool Keypoints with Synthetic Training Data Bram Vanherle, Jeroen Put, Nick Michiels and Frank Van Reeth In: Galambos, P., Kayacan, E., Madani, K. (eds) Robotics, Computer Vision and Intelligent Systems. ROBOVIS ROBOVIS 2020 2021. Communications in Computer and Information Science, vol 1667. Springer, Cham. AbstractIn this paper an end-to-end technique is presented to create a deep learning model to detect 2D keypoint locations from RGB images. This approach is specifically applied to tools, but can be used on other objects as well. First, 3D models of similar objects are sourced form the internet to avoid the need for exact textured models of the target objects. It is shown in this paper that these exact 3D models are not needed. To avoid the high cost of manually creating a data set, an image generation technique is introduced that is specifically created to generate synthetic training data for deep learning models. Special care was taken when designing this method to ensure that models trained on this data generalize well to unseen, real world data. A neural network architecture, Intermediate Heatmap Model (IHM), is presented that can generate probability heatmaps to predict keypoint locations. This network is equipped with a type of intermediate supervision to improve the results on real world data, when trained on synthetic data. A number of other tricks are employed to ensure generalisation towards real world images. A dataset of real tool images is created to validate this approach. Validation shows that the proposed method works well on real world images. Comparison to two other techniques shows that this method outperforms them. Additionally, it is investigated which deep learning techniques, such as transfer learning and data augmentation, help towards generalization on real data. Code to reproduce results is available at https://bvanherle.github.io/synthetic_tools. |
2021
 |
Adaptive Streaming and Rendering of Static Light Fields in the Web Browser Hendrik Lievens, Maarten Wijnants, Brent Zoomers, Jeroen Put, Nick Michiels and Peter Quax and Wim Lamotte In International Conference on 3D Immersion, IC3D 2021, Brussels, Belgium, December 8, 2021 IEEE, 2021. AbstractStatic light fields are an image-based technology that allowfor the photorealistic representation of inanimate objects andscenes in virtual environments. As such, static light fieldshave application opportunities in heterogeneous domains, in-cluding education, cultural heritage and entertainment. Thispaper contributes the design, implementation and performanceevaluation of a web-based static light field consumption sys-tem. The proposed system allows static light field datasets tobe adaptively streamed over the network and then to be visu-alized in a vanilla web browser. The performance evaluationresults prove that real-time consumption of static light fieldsat AR/VR-compatible framerates of 90 FPS or more is fea-sible on commercial off-the-shelf hardware. Given the ubiq-uitous availability of web browsers on modern consumptiondevices (PCs, smart TVs, Head Mounted Displays, . . . ), ourwork is intended to significantly improve the accessibility andexploitation of static light field technology. The JavaScriptclient code is open-sourced to maximize our work’s impact |
 |
Automatic Camera Control and Directing with an Ultra-High-Definition Collaborative Recording System Bram Vanherle, Tim Vervoort, Nick Michiels and Philippe Bekaert In European Conference on Visual Media Production (CVMP ’21), December 6–7, 2021, London, United Kingdom. ACM, New York, NY, USA, 10 pages. AbstractCapturing an event from multiple camera angles can give a viewer the most complete and interesting picture of that event. To be suitable for broadcasting, a human director needs to decide what to show at each point in time. This can become cumbersome with an increasing number of camera angles. The introduction of omnidirectional or wide-angle cameras has allowed for events to be captured more completely, making it even more difficult for the director to pick a good shot. In this paper, a system is presented that, given multiple ultra-high resolution video streams of an event, can generate a visually pleasing sequence of shots that manages to follow the relevant action of an event. Due to the algorithm being general purpose, it can be applied to most scenarios that feature humans. The proposed method allows for online processing when real-time broadcasting is required, as well as offline processing when the quality of the camera operation is the priority. Object detection is used to detect humans and other objects of interest in the input streams. Detected persons of interest, along with a set of rules based on cinematic conventions, are used to determine which video stream to show and what part of that stream is virtually framed. The user can provide a number of settings that determine how these rules are interpreted. The system is able to handle input from different wide-angle video streams by removing lens distortions. Using a user study it is shown, for a number of different scenarios, that the proposed automated director is able to capture an event with aesthetically pleasing video compositions and human-like shot switching behavior. |
 |
Real-time Detection of 2D Tool Landmarks with Synthetic Training Data Bram Vanherle, Jeroen Put, Nick Michiels and Frank Van Reeth In proceedings of the International Conference on Robotics, Computer Vision and Intelligent Systems (ROBOVIS '21), October 27–28, 2021, Online Streaming. AbstractIn this paper a deep learning architecture is presented that can, in real time, detect the 2D locations of certain landmarks of physical tools, such as a hammer or screwdriver. To avoid the labor of manual labeling, the network is trained on synthetically generated data. Training computer vision models on computer generated images, while still achieving good accuracy on real images, is a challenge due to the difference in domain. The proposed method uses an advanced rendering method in combination with transfer learning and an intermediate supervision architecture to address this problem. It is shown that the model presented in this paper, named Intermediate Heatmap Model (IHM), generalizes to real images when trained on synthetic data. To avoid the need for an exact textured 3D model of the tool in question, it is shown that the model will generalize to an unseen tool when trained on a set of different 3D models of the same type of tool. IHM is compared to two existing approaches to keypoint detection and it is shown that it outperforms those at detecting tool landmarks, trained on synthetic data. |
2018
 |
GPU-accelerated CellProfiler Imen Chakroun, Nick Michiels and Roel Wuyts In proceedings of the IEEE International Conference on Bioinformatics and Biomedicine (BIBM 2018), Madrid, 3-6 December 2018. AbstractCellProfiler excels at bridging the gap between advanced image analysis algorithms and scientists who lack computational expertise. It lacks however high performance capabilities needed for High Throughput Imaging experiments where workloads reach hundreds of TB of data and are computationally very demanding. In this work, we introduce a GPU-accelerated CellProfiler where the most time-consuming algorithmic steps are executed on Graphics Processing Units. Experiments on a benchmark dataset showed significant speedup over both single and multi-core CPU versions. The overall execution time was reduced from 9.83 Days to 31.64 Hours. |
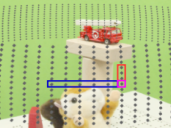 |
Standards-compliant HTTP Adaptive Streaming of Static Light Fields Maarten Wijnants, Hendrik Lievens, Nick Michiels, Jeroen Put, Peter Quax and Wim Lamotte In proceedings of the ACM Symposium on Virtual Reality Software and Technology (VRST 2018), Tokyo, Japan, November 28 - December 1, 2018. AbstractStatic light fields are an effective technology to precisely visualize complex inanimate objects or scenes, synthetic and real-world alike, in Augmented, Mixed and Virtual Reality contexts. Such light fields are commonly sampled as a collection of 2D images. This sampling methodology inevitably gives rise to large data volumes, which in turn hampers real-time light field streaming over best effort networks, particularly the Internet. This paper advocates the packaging of the source images of a static light field as a segmented video sequence so that the light field can then be interactively network streamed in a quality-variant fashion using MPEG-DASH, the standardized HTTP Adaptive Streaming scheme adopted by leading video streaming services like YouTube and Netflix. We explain how we appropriate MPEG-DASH for the purpose of adaptive static light field streaming and present experimental results that prove the feasibility of our approach, not only from a networking but also a rendering perspective. In particular, real-time rendering performance is achieved by leveraging video decoding hardware included in contemporary consumer-grade GPUs. Important trade-offs are investigated and reported on that impact performance, both network-wise (e.g., applied sequencing order and segmentation scheme for the source images of the static light field) and rendering-wise (e.g., disk-versus-GPU caching of source images). By adopting a standardized transmission scheme and by exclusively relying on commodity graphics hardware, the net result of our work is an interoperable and broadly deployable network streaming solution for static light fields. |
 |
Capturing Industrial Machinery into Virtual Reality Jeroen Put, Nick Michiels, Fabian Di Fiore and Frank Van Reeth In proceedings of Articulated Motion and Deformable Objects 2018 (AMDO 2018), Springer International Publishing, Cham, July 2018. AbstractIn this paper we set out to find a new technical and commercial solution to easily acquire a virtual model of existing machinery for visualisation in a VR environment. To this end we introduce an image-based scanning approach with an initial focus on a monocular (handheld) capturing device such as a portable camera. Poses of the camera will be estimated with a Simultaneous Localisation and Mapping technique. Depending on the required quality offline calibration is incorporated by means of ArUco markers placed within the captured scene. Once the images are captured, they are compressed in a format that allows rapid low-latency streaming and decoding on the GPU. Finally, upon viewing the model in a VR environment, an optical flow method is used to interpolate between the triangulisation of the captured viewpoints to deliver a smooth VR experience. We believe our tool will facilitate the capturing of machinery into VR providing a wide range of benefits such as doing marketing, providing offsite help and performing remote maintenance. |
2016
 |
Representations and Algorithms for Interactive Relighting Nick Michiels, Advisor: Philippe Bekaert, Doctoral Dissertation, Hasselt University, Belgium, December 2016. AbstractClassic relighting applications are striving to unite the virtual world and the real world by applying computer graphics algorithms to pixel and image-based descriptions. This has allowed them to apply new virtual lighting conditions on real images as well as inserting virtual objects in real environments under credible lighting conditions. However, state-of-the-art representations for geometry, materials and lighting often limit the capabilities and quality of the simulation of light in relighting applications. Spherical harmonics allow for a fast simulation of light, but can only handle low-frequency lighting effects efficiently. In addition, other relighting applications rely on Haar wavelets; which are capable of representing highfrequency lighting information as well as having great compression performance. In theory, Haar wavelets have an efficient forward rendering evaluation method. However, in practice, they need a complex rotation operator and the three factors of the rendering equation can not be constructed dynamically. In addition, they lack smoothness, which is essential for relighting applications. To overcome most of these constraints, this dissertation researched other, possibly better, representations. This dissertation introduces two new underlying basis representations designed to improve cutting edge relighting algorithms. First, we will introduce an efficient algorithm to calculate the triple product integral binding coefficients for a heterogeneous mix of wavelet bases. As mentioned above, Haar wavelets excel at encoding piecewise constant signals, but are inadequate for compactly representing smooth signals for which high-order wavelets are ideal. Our algorithm provides an efficient way to calculate the tensor of these binding coefficients, which is essential for the correct evaluation of the light transport integral. The algorithm exploits both the hierarchical nature and vanishing moments of the wavelet bases, as well as the sparsity and symmetry of the tensor. The effectiveness of high-order wavelets will be demonstrated in a rendering application. The smoother wavelets represent the signals more effectively and with less blockiness than their Haar wavelet counterpart. Using a heterogeneous mix of wavelets allows us to overcome the smoothness problem. However, wavelets still constrain one or several factors of the rendering equation, keeping them inadequate for more interactive rendering applications. For example, visibility is often precalculated and animations are not allowed; and changes in lighting are limited to a simple rotation and are not very detailed. Other techniques compromise on quality and often coarsely tabulate BRDF functions. In the second part of this dissertation, we research how spherical radial basis functions (SRBFs) can be used to overcome most of these problems. SRBFs have already been used in forward rendering, but they still do not guarantee full interactivity of the underlying factors of geometry, materials and lighting. We argue that an interactive representation of the factors is crucial and will greatly improve the flexibility and efficiency of a relighting algorithm. In order to dynamically change lighting conditions or alter scene geometry and materials, these three factors need to be converted to the SRBF representation in a fast manner. This dissertation presents a method to perform the SRBF data construction and rendering in real-time. To support dynamic high-frequency lighting, a multiscale residual transformation algorithm is applied. Area lights are detected through a peak detection algorithm. By using voxel cone tracing and a subsampling scheme, animated geometry casts soft shadows dynamically. At this point, we have two new approaches for evaluating triple product rendering integrals with fewer coefficients and an advantageous smoothness behavior. But how will they perform in actual relighting applications? We tried to answer this question in the final part of this dissertation by conducting experiments in two distinct use cases. A first use case focuses on the relighting of virtual objects with real lighting information of existing scenes. To demonstrate this, we have developed an augmented reality application. The ambition is to augment omnidirectional video, also called 360 degrees video, with natural lit virtual objects and to make the experience more realistic for users. Recent years have known a proliferation of real-time capturing and rendering methods for omnidirectional video. Together with these technologies, rendering devices such as virtual reality glasses have tried to increase the immersive experience of users. Structure-from-motion is applied to the omnidirectional video to reconstruct the trajectory of the camera. Then, the position of an inserted virtual object is linked to the appropriate 360 degrees environment map. State-of-the-art augmented reality applications have often lacked realistic appearance and lighting, but our spherical radial basis rendering framework is capable of evaluating the rendering equation in real-time with fully dynamic factors. The captured omnidirectional video can be directly used as lighting information by feeding it to our renderer, where it is instantly transformed to the proper SRBF basis. We demonstrate an application in which a computer generated vehicle can be controlled through an urban environment. The second use case addresses the relighting of real objects. It will show more practical examples of how an improved representation will influence the quality and time performance of existing inverse rendering and intrinsic image decomposition applications. Such relighting techniques try to extract geometry, material and lighting information of real scenes out of one or multiple input images. First, we show how an inverse rendering technique, as introduced by Haber et al. [Haber et al., 2009], would benefit from the smooth behavior of our high-order wavelet or SRBF representation. To allow for a hierarchical optimization algorithm, where the lower level coefficients are estimated first and then more detailed coefficients are inserted based on the well-posedness of the system, it is essential that the lower level coefficients are good approximates of the signal to estimate and thus have a smooth behavior. Besides a better refinement method, we also show how an integration with our SRBF triple product renderer will reduce the execution time of the optimization process from hours to minutes. Then, in a second application, we conduct experiments on the existing intrinsic image decomposition problem of Barron and Malik [Barron and Malik, 2015], where we used our SRBF renderer in combination with a prior based optimization method. We achieve this by adapting the SRBF rendering framework to export the proper gradients for the L-BFGS minimization step. |
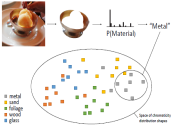 |
Material-Specific Chromaticity Priors Jeroen Put, Nick Michiels and Philippe Bekaert, In proceedings of The 27th British Machine Vision Conference (BMVC 2016), BMVA Press, York, UK, September 2016. AbstractRecent advances in machine learning have enabled the recognition of high-level categories of materials with a reasonable accuracy. With these techniques, we can construct a per-pixel material labeling from a single image. We observe that groups of high-level material categories have distinct chromaticity distributions. This fact can be used to predict the range of the absolute chromaticity values of objects, provided the material is correctly labeled. We explore whether these constraints are useful in the context of the intrinsic images problem. This paper describes how to leverage material category identification to boost estimation results in state-of-the-art intrinsic images datasets. |
2015
 |
Using Near-Field Light Sources to Separate Illumination from BRDF Jeroen Put, Nick Michiels and Philippe Bekaert, In proceedings of The 26th British Machine Vision Conference (BMVC 2015), pp. 16.1-16.13, BMVA Press, Swansea, UK, September 2015. AbstractSimultaneous estimation of lighting and BRDF from multi-view images is an interesting problem in computer vision. It allows for exciting applications, such as flexible relighting in post-production, without recapturing the scene. Unfortunately, the estimation problem is made difficult because lighting and BRDF have closely entangled effects in the input images. This paper presents an algorithm to support both the estimation of distant and near-field illumination. Previous techniques are limited to distant lighting. We contribute by proposing an additional factorization of the lighting, while keeping the rendering efficient and additional data compactly stored in the wavelet domain. We reduce complexity by clustering the scene geometry into a few groups of important emitters and calculate the emitting powers by alternately solving for illumination and reflectance. We demonstrate our work on a synthetic and real datasets and show that a clean separation of distant and near-field illumination leads to a more accurate estimation and separation of lighting and BRDF. |
 |
Interactive Relighting of Virtual Objects under Environment Lighting
Nick Michiels, Jeroen Put and Philippe Bekaert, In proceedings of The 10th International Conference on Computer Graphics Theory and Applications (GRAPP 2015), pp. 220-228, Berlin, Germany, March 2015. AbstractCurrent relighting applications often constrain one or several factors of the rendering equation to keep the rendering speed real-time. For example, visibility is often precalculated and animations are not allowed, changes in lighting are limited to simple rotation or the lighting is not very detailed. Other techniques compromise on quality and often coarsely tabulate BRDF functions. In order to solve these problems, some techniques have started to use spherical radial basis functions. However, solving the triple product integral does not guarantee interactivity. In order to dynamically change lighting conditions or alter scene geometry and materials, these three factors need to be converted to the SRBF representation in a fast manner. This paper presents a method to perform the SRBF data construction and rendering in real-time. To support dynamic high-frequency lighting, a multiscale residual transformation algorithm is applied. Area lights are detected through a peak detection algorithm. By using voxel cone tracing and a subsampling scheme, animated geometry casts soft shadows dynamically. We demonstrate the effectiveness of our method with a real-time application. Users can shine with multiple light sources onto a camera and the animated virtual scene is relit accordingly.Results |
2014
 |
Interactive Augmented Omnidirectional Video with Realistic Lighting
Nick Michiels, Lode Jorissen, Jeroen Put and Philippe Bekaert, In proceedings of The International Conference on Augmented and Virtual Reality (SALENTO AVR 2014), pp. 247-263, Lecce, Italy, September 2014. AbstractThis paper presents the augmentation of immersive omnidirectional video with realistically lit objects. Recent years have known a proliferation of real-time capturing and rendering methods of omnidirectional video. Together with these technologies, rendering devices such as Oculus Rift have increased the immersive experience of users. We demonstrate the use of structure from motion on omnidirectional video to reconstruct the trajectory of the camera. The position of the car is then linked to an appropriate 360 degrees environment map. State-of-the-art augmented reality applications have often lacked realistic appearance and lighting. Our system is capable of evaluating the rendering equation in real-time, by using the captured omnidirectional video as a lighting environment. We demonstrate an application in which a computer generated vehicle can be controlled through an urban environment.Results
|
|
 |
Product Integral Binding Coefficients for High-order Wavelets
Nick Michiels, Jeroen Put and Philippe Bekaert, In proceedings of The 11th International Conference on Signal Processing and Multimedia Applications (SIGMAP 2014), pp 17-24., Vienna, Austria, August 2014. AbstractThis paper provides an efficient algorithm to calculate product integral binding coefficients for a heterogeneous mix of wavelet bases. These product integrals are ubiquitous in multiple applications such as signal processing and rendering. Previous work has focused on simple Haar wavelets. Haar wavelets excel at encoding piecewise constant signals, but are inadequate for compactly representing smooth signals for which high-order wavelets are ideal. Our algorithm provides an efficient way to calculate the tensor of these binding coefficients. The algorithm exploits both the hierarchical nature and vanishing moments of the wavelet bases, as well as the sparsity and symmetry of the tensor. We demonstrate the effectiveness of high-order wavelets with a rendering application. The smoother wavelets represent the signals more effectively and with less blockiness than the Haar wavelets of previous techniques. |
|
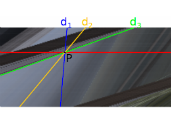 |
A qualitative comparison of MPEG view synthesis and light field rendering
Lode Jorissen, Patrik Goorts, Bram Bex, Nick Michiels, Sammy Rogmans, Philippe Bekaert and Gauthier Lafruit, In proceedings of 3DTV-Conference: The True Vision - Capture, Transmission and Display of 3D Video (3DTV-CON 2014), pp. 1-4, Budapest, Hungary, July 2014. AbstractFree Viewpoint Television (FTV) is a new modality in next generation television, which provides the viewer free navigation through the scene, using image-based view synthesis from a couple of camera view inputs. The recently developed MPEG reference software technology is, however, restricted to narrow baselines and linear camera arrangements. Its reference software currently implements stereo matching and interpolation techniques, designed mainly to support three camera inputs (middle-left and middleright stereo). Especially in view of future use case scenarios in multi-scopic 3D displays, where hundreds of output views are generated from a limited number (tens) of wide baseline input views, it becomes mandatory to fully exploit all input camera information to its maximal potential. We therefore revisit existing view interpolation techniques to support dozens of camera inputs for better view synthesis performance. In particular, we show that Light Fields yield average PSNR gains of approximately 5 dB over MPEG's existing depth-based multiview video technology, even in the presence of large baselines. |
|
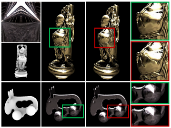 |
Exploiting Material Properties to Select a Suitable Wavelet Basis for Efficient Rendering
Jeroen Put, Nick Michiels and Philippe Bekaert, In proceedings of The 9th International Conference on Computer Graphics Theory and Applications (GRAPP 2014), pp. 218-224, Lisbon, Portugal, Januari 2014. AbstractNearly-orthogonal spherical wavelet bases can be used to perform rendering at higher quality and with significantly less coefficients for certain spherical functions, e.g. BRDF data. This basis avoids parameterisation artifacts from previous 2D methods, while at the same time retaining high-frequency details in the lighting. This paper demonstrates the efficiency of this representation for rendering purposes. Regular 2D Haar wavelets can still occasionally perform better, however. This is due to their property of being fully orthogonal. An important novelty of this paper lies in the introduction of a technique to select an appropriate wavelet basis on-the-fly, by utilising prior knowledge of materials in the scene. To show the influence of different bases on rendering quality, we perform a comparison of their parameterisation error and the compression performance. |

2013
 |
High-order wavelets for hierarchical refinement in inverse rendering
Nick Michiels, Jeroen Put, Tom Haber, Martin Klaudiny and Philippe Bekaert, In Poster proceedings of The 40th International Conference and Exhibition on Computer Graphics and Interactive Techniques (SIGGRAPH 2013), pp. 99-99, Anaheim, California, USA, August 2013. AbstractIt is common to use factored representation of visibility, lighting and BRDF in inverse rendering. Current techniques use Haar wavelets to calculate these triple product integrals efficiently [Ng et al. 2004]. Haar wavelets are an ideal basis for the piecewise constant visibility function, but suboptimal for the smoother lighting and material functions. How can we leverage compact high-order wavelet bases to improve efficiency, memory consumption and accuracy of an inverse rendering algorithm? If triple product integrals can be efficiently calculated for higher-order wavelets, the reduction in coefficients will reduce the number of calculations, therefore improving performance and memory usage. Some BRDFs can be stored five times more compactly.Current inverse rendering algorithms rely on solving large systems of bilinear equations [Haber et al. 2009]. We propose a hierarchical refinement algorithm that exploits the tree structure of the wavelet basis. By only splitting at interesting nodes in the hierarchy, large portions of less important coefficients can be skipped. The key of this algorithm is only splitting nodes of the wavelet tree that contribute to the solution of the system M (see Algorithm 1). It is critical to use high-order wavelets for this, as Haar wavelets can only introduce high frequencies which lead to blockiness. |
2011
 |
Scene acquisition using structured light and registration
Nick Michiels, Bert De Decker, Tom Haber and Philippe Bekaert, Master Dissertation, Hasselt University, Diepenbeek, Belgium, July, 2011. AbstractBuilding 3D models from existing objects in the world is a fast growing domain of computer vision and computer graphics. It is used within various projects such as for example entertainment or archeology. In combination with the progress on computer technology and affordable hardware, it is possible to render this dense 3D information.This master thesis describes an active correspondence technique, i.e. structured light, which obtains the 3D information from a scene using only a camera and projector. The thesis introduces a number of structured light patterns that can be used and that may or may not allow to solve the correspondence problem. A first category of patterns is called time-multiplexing. These are very robust and can obtain a large number of correspondences. The main drawback is that they can’t be used for moving scenes. In such situations it is better to use spatial neighborhood patterns. A spatial neighborhood pattern codes the position of a pixel in a pattern based on the neighborhood of the pixel. This makes it possible to code all the information in only one pattern. The most popular and formal technique based on a spatial neighborhood scheme are using De Bruijn sequences. In addition, there are also a number of non-formal spatial neighborhood patterns discussed. There will be shown that the choice of a good pattern in combination with a global optimization technique, i.e. Dynamic Programming, allows it to obtain a 3D point cloud out of a single captured frame. The camera moves through the scene and for every frame the structured light technique obtains a 3D point cloud. These point clouds each have a different view of the scene. To obtain a full model of the scene, it is necessary that all these point clouds will be merged together. This step is the so called Registration of point clouds. The most popular technique is Iterative Closest Point (ICP), which searches iteratively for the best transformation to slide a point cloud in another one. These thesis will describe a great amount of alternatives of ICP, for example the use of geometric parameters (i.e. normal and curvature). The results will show that ICP is very robust for highly similar point clouds. But the algorithm faces many problems when the point cloud doesn’t overlap enough or does not contain enough depth. Results
|



2009
 |
Augmented Reality for Workbenches
Nick Michiels, Tom Cuypers, Yannick Francken and Philippe Bekaert, Bachelor Dissertation, Hasselt University, Diepenbeek, Belgium, July, 2009. AbstractIn this bachelor thesis I’ll try to recognize objects of a workbench by videotaping the workbench. This objects will be replaced by new projected objects. To accomplish this we need a workbench on which we project. Besides the projector we also videotape the workbench. In my setup I will place the projector en videotape perpendicular to the workbench. In the beginning I only use blank pages as objects. There are no distinctions between the pages.To accomplish this bachelor thesis there are some steps we must follow:- First we have the calibration. We need a calibration step to know the exact relationship between the coordinates of the screen and the coordinates of the workbench. This step will be fully automatic.- The second step is the image recognition. We have some incoming frames from the camera. Our job is to distinguish the blank pages from the workbench.- If the separation of the blank pages is done we can map the projection to the coordinates of the blank pages (expressed in coordinates of the workbench). At this point we are ready to project onto the workbench. This step also includes a mechanism to detect a rotation or translation of the blank page as fast as possible. The projection should be updated as fast as possible.My second goal is to create something like the Toolkit library. The main purpose is to give every blank page a marker. This marker will be recognized in the step of image recognition. Corresponding to the marker, the projector can treat each page different. For example on one page we project a movie while on the other we project a pdf. I’ll also do some research for choosing the marker as best as possible. As an extra I could recognize several kinds of objects and not just blank pages anymore. As second extension I could make a second setup and make a network between the two setups. |